

Overview:
In this tutorial, I would like to demo Reactor Buffer vs Window options for collecting the items in a reactive pipeline & doing operations in batches.
If you are new to reactive programming or project reactor, take a look at this entire series to get a good idea on that.
Reactor Buffer vs Window:
Reactive programming is a style of programming which observes on the data streams, reacting to the changes and propagating them! The data stream will be closed when there is no more data for source to emit or when there is an un-handled exception!
The data stream could be unbounded / never ending stream! In the reactive pipeline, we could have some operations which need to be executed for every item. Sometimes, instead of executing the operations for every item one by one, we could collect the item periodically and execute the operations for all the collected items at once or we might want to perform some aggregate operations on the set.
This is where Reactor Buffer & Window options would be very helpful.
- Reactor Buffer: to collect the items as a list within the Flux
- Reactor Window: to emit a collection of items as a Flux within the Flux.
Reactor Buffer:
Let’s consider a service in an application which is supposed to collect all the audit-events happening among all other systems in the application, process them and store them in a Database. For an extremely high throughput application, we can not process and store these events in the DB one by one as it could affect the overall processing time. Instead we might want to collect them in batches and do a bulk insert.
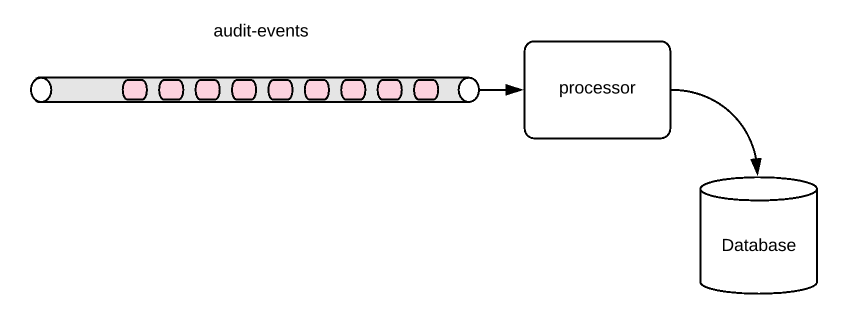
Let’s assume that we would like to collect 100 items at a time and store them. But this approach has an issue as well. What if we had received only 99 items? The 100th item has not yet arrived for a while. what will happen in the case? Our application will wait forever for the 100th item to arrive. So we might want something like either 100 items or 10 seconds – whichever come first, we will do the processing and store them in the DB. This sounds a lot better.
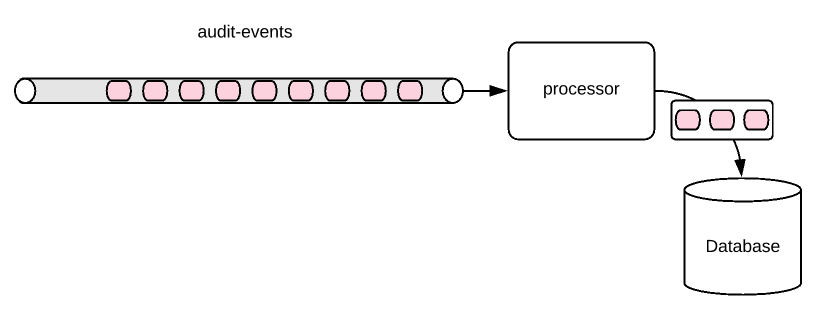
Another example could be to detect credit cards which are used 3 times within 2 seconds (just an example!). In that case, something is wrong! It could be a fraudulent activity and the card should be blocked! Even though this requirement sounds very simple, it would be very challenging to implement!
Let’s see how we can accomplish this using reactive programming using project Reactor. Project Reactor provides 2 high level options with many method overloading options.
Reactor Buffer – Example:
- Collecting 5 elements at a time:
Flux.range(1,20)
.delayElements(Duration.ofMillis(500))
.buffer(5) // collect the items in batches of 5
.subscribe(l -> System.out.println("Received :: " + l));// output:
Received :: [1, 2, 3, 4, 5]
Received :: [6, 7, 8, 9, 10]
Received :: [11, 12, 13, 14, 15]
Received :: [16, 17, 18, 19, 20]- Collecting elements every 3 seconds:
Flux.range(1,20)
.delayElements(Duration.ofMillis(500))
.buffer(Duration.ofSeconds(3)) // collect the items every 3 seconds
.subscribe(l -> System.out.println("Received :: " + l));// output
Received :: [1, 2, 3, 4, 5]
Received :: [6, 7, 8, 9, 10]
Received :: [11, 12, 13, 14, 15]
Received :: [16, 17, 18, 19, 20]- Collecting 5 elements / every 3 seconds:
Flux<Integer> elements1 = Flux.range(1, 10)
.delayElements(Duration.ofMillis(500));
Flux<Integer> elements2 = Flux.range(101, 10)
.delayElements(Duration.ofMillis(600));
Flux.merge(elements1, elements2)
.bufferTimeout(5, Duration.ofSeconds(3)) // collect 5 items every 3 seconds
.subscribe(l -> System.out.println("Received :: " + l));// output
Received :: [1, 101, 2, 102, 3]
Received :: [103, 4, 104, 5, 105]
Received :: [6, 7, 106, 8, 107]
Received :: [9, 108, 10, 109, 110]- Overlapping Buffer:
Sometimes we might to have overlapping buffers as shown below.
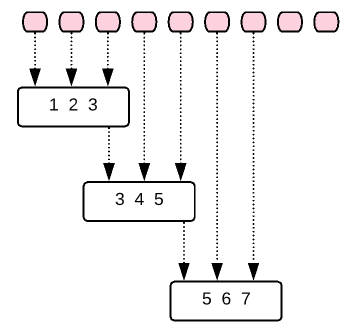
Flux.range(1, 10)
.buffer(3, 2) // collect 3, skip 2 then collect 3
.subscribe(l -> System.out.println("Received :: " + l));// output:
Received :: [1, 2, 3]
Received :: [3, 4, 5]
Received :: [5, 6, 7]
Received :: [7, 8, 9]
Received :: [9, 10]- Dropping Buffer:
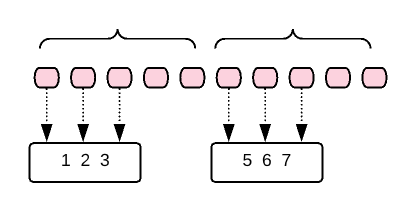
Flux.range(1, 10)
.buffer(3, 5) // collect 3 for every 5 items
.subscribe(l -> System.out.println("Received :: " + l));// output:
Received :: [1, 2, 3]
Received :: [6, 7, 8]- Buffer until we see a different value
Flux.just(1,2,2,2,3,2,2,3,3,3,4,5)
.bufferUntilChanged()
.subscribe(l -> System.out.println("Received :: " + l));// output
Received :: [1]
Received :: [2, 2, 2]
Received :: [3]
Received :: [2, 2]
Received :: [3, 3, 3]
Received :: [4]
Received :: [5]Reactor Window:
Reactor Window is more or less same like Reactor Buffer – but it creates a branch in the Flux instead of collecting them as list as buffering does.
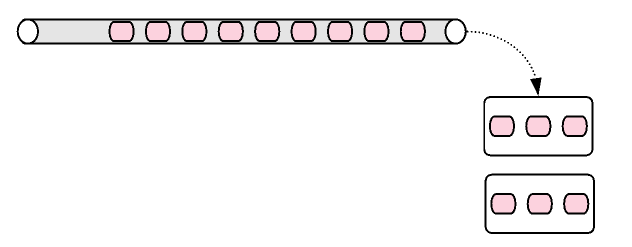
For example, buffering behavior would be like this. Collecting 3 elements at a time. Resulting type would be Flux<List<T>>
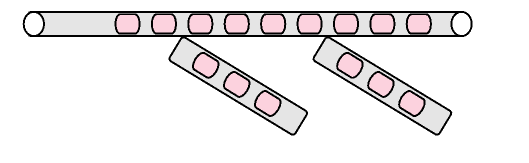
Windowing behavior would be like opening a separate Flux for every 3 items. Resulting type would be Flux<Flux<T>>
- To split the original Flux into Flux of containing 5 items
Flux.range(1, 10)
.window(5)
.doOnNext(flux -> flux.collectList().subscribe(l -> System.out.println("Received :: " + l)))
.subscribe();// output
Received :: [1, 2, 3, 4, 5]
Received :: [6, 7, 8, 9, 10]- It has almost all the methods as we saw buffer options above. For ex:
- .window(Duration.ofSeconds(3)) to create Flux every 3 seconds
- .window(3, 2) To create overlapping Flux
Reactor Window – Fraud Detection Demo:
Let’s consider streams of credit card transactions. As per our business rule, If a credit card is used 3 times in the last 2 seconds, then something is wrong! It could be a fraudulent activity and the card should be blocked! Even though this requirement sounds very simple, it would be very challenging to implement without windowing!
// creditcard stream 1
Flux<Integer> transactions1 = Flux.just(100, 101, 102, 100, 105, 102, 104)
.delayElements(Duration.ofMillis(500));
// creditcard stream 2
Flux<Integer> transactions2 = Flux.just(101, 200, 201, 300, 102, 301, 100)
.delayElements(Duration.ofMillis(600));
// business rule for fraud detection
private void fraudDetector(Flux<Integer> transactions){
transactions
.collectList().map(l -> l.stream().collect(Collectors.groupingBy(Function.identity(), Collectors.counting())))
.doOnNext(map -> map.entrySet().removeIf(entry -> entry.getValue() < 3))
.filter(map -> !map.isEmpty())
.map(Map::keySet)
.subscribe(s -> System.out.println("Fraud Cards :: " + s));
}
// Flux windowing
Flux.merge(transactions1, transactions2)
.window(Duration.ofSeconds(2), Duration.ofMillis(500)) // create a flux of 2 seconds every 500 milliseconds
.doOnNext(this::fraudDetector)
.subscribe();// output:
Fraud Cards :: [102]Grouping:
There is also one more way of grouping the elements based on some condition. For example, We might want to collect based on some category! Splitting the flux into Odd and even numbers flux.
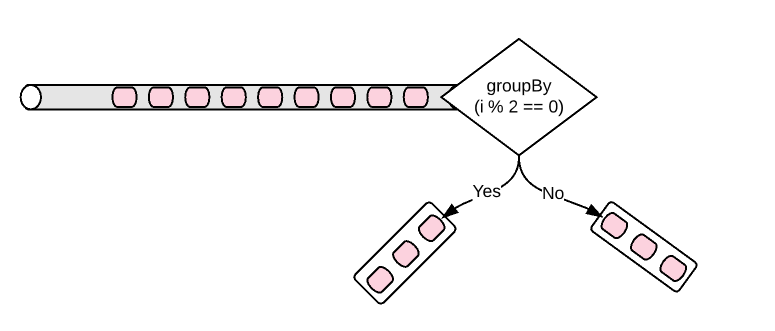
Lets assume that I would like to collect the elements based on the remainder when I divide the number by 3.
@Data
@AllArgsConstructor
@ToString
public class RemainderCollector {
private int remainder;
private List<Integer> items;
}The groupBy method returns a GroupedFlux which has a key method that can be used to find the key for which the element belongs to!
Flux.range(1, 30)
.groupBy(i -> i % 3)
.flatMap(gf -> gf.collectList().map(l -> new RemainderCollector(gf.key(), l)))
.subscribe(System.out::println);Output:
RemainderCollector(remainder=0, items=[3, 6, 9, 12, 15, 18, 21, 24, 27, 30])
RemainderCollector(remainder=1, items=[1, 4, 7, 10, 13, 16, 19, 22, 25, 28])
RemainderCollector(remainder=2, items=[2, 5, 8, 11, 14, 17, 20, 23, 26, 29])As you see we have grouped elements based on the remainder.
Note:
Be cautious when you use this groupBy. The number of result-set should be low if possible and there should also be downstream consumers to drain the elements.
Summary:
We were able to successfully demonstrate & understand the difference between Reactor Buffer vs Window methods.
Read more about Reactive Programming.
Happy coding 🙂
{kind=link}